As children, we’re told bedtime stories to help us fall asleep at night. Stories about mythical creatures, princes and princesses, and unsung superheroes take us to an alternate reality, a more comfortable reality. There, everything is better — we’re more adventurous, life is more exciting, and we always win the battle between good and evil.
But what happens when we grow up? For most, the storytelling ceases and is reserved only for fictional novels, TV shows, and cinema. For others, the storytelling never stops. They live in it, taking misleading headlines and fake news as ground truth. While this is sometimes harmless, like feeling a little better about a glass of red wine they had the night before, it can also lead to dangerous precedents, like COVID-19 conspiracy theorists beingmore likely to refuse to wear masks.
Technology has enabled this warped perception of reality. Increasingly, our lives exist behind screens. And here is where the distortion of truth occurs.
In this post…
- How truth was lost in technological innovation
- The impact of social media on historical centers of knowledge and modern-day information consumption
- The case for reframing disinformation as a security issue and a business opportunity
- Current disinformation solutions and the market landscape for disinformation defense startups
- The challenges ahead
Technology’s Impact on Truth
Throughout history, truth has been presented through three mediums: text, visuals, and sounds. In centuries past, we read about current events through physical newspapers and consumed information through books. We sawevents happen around us. And we heard from friends and family about anything happening within our circles.
Today, all of these mechanisms for delivering information still exist, but instead, are collectively embedded on our social media feeds. Algorithms amplify the voices within our inner circles and recommend accounts according to our calculated preferences, creating “personalized” content that fills our entire feeds. The result? Billions of individual echo chambers, where our own realities and truths live.
“If a tree falls in a forest and no one is around to hear it, does it make a sound?”
When Alice fell down the rabbit hole, she was really entering figments of her own imagination. When we fall into rabbit holes on the internet, we are really entering figments of our own subconscious — articles, videos, and images that recommendation algorithms think we’ll like, based on our own codified browsing and online interaction history.https://cdn.embedly.com/widgets/media.html?type=text%2Fhtml&key=a19fcc184b9711e1b4764040d3dc5c07&schema=twitter&url=https%3A//twitter.com/dipalua_/status/1309327844418314240&image=
Our Changing Relationship with Information Consumption
While these recommendations have served us well for discovering cute babyand dog videos, they have also worked to alter our main modes of factual information consumption, enabling dangerous new artificial realities. Social media is becoming our choice news source, with 1 in 5 adults reading political news primarily from their feeds. This trend will increase with time, considering this behavior is heavily concentrated in younger demographics, with a striking 48% of 18–29 year-olds consuming their news primarily through social media — often daily.

A major decentering of ground truth is happening, shifting from traditional media behemoths to individualized, algorithmically-driven feeds. After all, it’s much easier to trust something that agrees with you. This has given rise to alternative social media platforms, like Parler and Gab, that capitalize on distrust in mainstream media and effectively foster extreme ideological polarization. These places become breeding grounds for conspiracy theories, like QAnon and Plandemic.
In the future, it’s not just going to be the elderly who are more susceptible to fake news. As long as social media platforms push content that optimizes for likeness, Gen Z and their younger counterparts will also become mis and disinformation superspreaders. One study found young people are actually more likely to believe COVID-19 misinformation (18% rate for those 18–24 vs. 9% for those over 65), highlighting how this problem will not simply disappear with generational turnover.
The Case for Reframing the Disinformation Problem
Mis and disinformation is not just a societal issue.
When we refer to it as solely such, by default, we place the responsibility of solving it into the hands of the people — it’s someone else’s problem, likely our elected officials. But if history has taught us anything, regulatory innovation moves slowly. Because of the disproportionate supply of right-leaning mis and disinformation, it has unnecessarily become an intensely politicized issue — any changes to Section 230 will be long and painful.
What will help is a reframing of the disinformation problem, a way to highlight that the long-term dangers outweigh the short-term gains and a way to quantify its damage in monetary terms.
Mis and disinformation is a security issue.
There are powerful nation-states who conduct coordinated disinformation campaigns to undermine election integrity, compromise national security, and instill distrust in the government. Over 70 countries have conducted disinformation campaigns. For them, their gains may be more politically motivated. But governments aren’t the only targets for disinformation — corporations are at risk too.
For instance, when the (debunked) conspiracy theory that 5G mobile networks spread COVID-19 first gained popularity this year, a number of arson attacks on European cell towers occurred, destroying physical assets owned by Vodafone, EE, o2, and Three. A few years ago, 4chan users launched a fake ad campaign against Starbucks to endanger undocumented immigrants under the guise of “#borderfreecoffee.” QAnon users have also worked to damage brand reputations, like Wayfair’s, when they pushedfalse theories of the e-commerce retailer trafficking children inside of the furniture it sells online. And now, as we soon approach distributing effective and safe COVID-19 vaccines to the public, there will inevitably be trending hashtags and viral posts intended to cast doubt on American healthcare officials.
Regardless of the intent, these campaigns serve as proof of concept for a host of new cyberattack strategies. We can imagine a future where the viral nature of mis and disinformation is commonly exploited for monetary gain by cybercriminals — pushing conspiracy theories for ad revenues, employing clickbait phishing tactics on falsehoods, destructing a competitor’s customer loyalty with misconstrued information, and developing new forms of ransomware with coordinated disinformation attacks.
“It’s time to change how we think about propaganda, disinformation, and false information: it’s not about fake news, it’s an adversarial attack in the information space.” — Yonder
Advances in technology, our modern double-edged sword, will further exacerbate the problem. Disinformation campaigns will become increasingly automated, enabled by technological advances in NLP transformers, synthetic data, and deepfake videos and images. Not only does technology increase disinformation’s prevalence, but it also makes it more difficult to reliably detect. Currently, mis and disinformation ML detection models vary in their precision — it’s easier to detect more extremist viewpoints, where there’s often an entire dedicated lexicon (e.g., QAnon’s “where we go one, we go all”). For more widespread, subtler forms of mis and disinformation like anti-vaxxer campaigns, it becomes increasingly difficult to discern disinformation from opinion. We can only imagine how much harder detection and moderation will become with increasingly human-like, automated disinformation campaigns. We’ve created a perfect storm for the next generation of information warfare.
Mis and disinformation is also a business opportunity that is applicable to all sectors.
Mis and disinformation thrive off of ad-driven business models. False information travels six times faster than true information — it’s a profitable venture. More engagement means more traffic, and more traffic means more money. When brands go to ad exchanges like Google Ads and AppNexus, they select sites with the highest monthly traffic, even if they are disinformation nodes. Efforts like the Global Disinformation Index to demonetize and delist disinformation sites on ad exchanges are a major step in the right direction. But adversaries are constantly finding new ways to profit, like selling merch on marketplaces like Amazon. Money is being made, and it is costing us big time.
“If you can create doubt, you can generate income in an attention economy by grabbing a user’s attention and then by selling that attention to others. Disinformation can be viewed as the new currency for those businesses.” — Camille D. Ryan, et al.
In 2019, mis and disinformation cost the global economy $78 billion, comprising some $17B from financial misinformation, $9 billion from health misinformation, and $9 billion from reputational misinformation. Considering the plethora of disinformation this year around COVID-19 and the presidential election, the financial impact will likely increase.
Current Solutions and the Opportunity for Disinformation Startups
So what do you do with slow-acting regulators, a seemingly infinite oncoming stream of hard-to-detect AI and human generated disinformation content, and a deeply misaligned business model? You can try to enact change from within tech companies — or — find a way to profit off of fighting disinformation.
How Disinformation is Combatted Today
To get a better picture of the work that goes into collecting training data on disinformation, I became a data-labeler on AWS’s Mechanical Turk platformfor a day and did a few tasks related to identifying fake news. After a few hours of tedious work reading and analyzing many blocks of text, I earned $1.03 in the form of an Amazon gift card (clearly my calling).
The data collection process for disinformation detection algorithms is notably more labor-intensive than others because of the need for human data labelers to apply subjective judgment (to discern satire, opinions, etc.). This is one of the reasons why it’s a difficult problem for big tech companies to solve purely algorithmically — they often need to incorporate a human-in-the-loop approach. I chatted with a number of individuals at companies like Twitter and non-profit research organizations like Election Integrity Partnership to understand what this looks like in practice. Below is a visual representation of the workflow for a typical disinformation defense team:
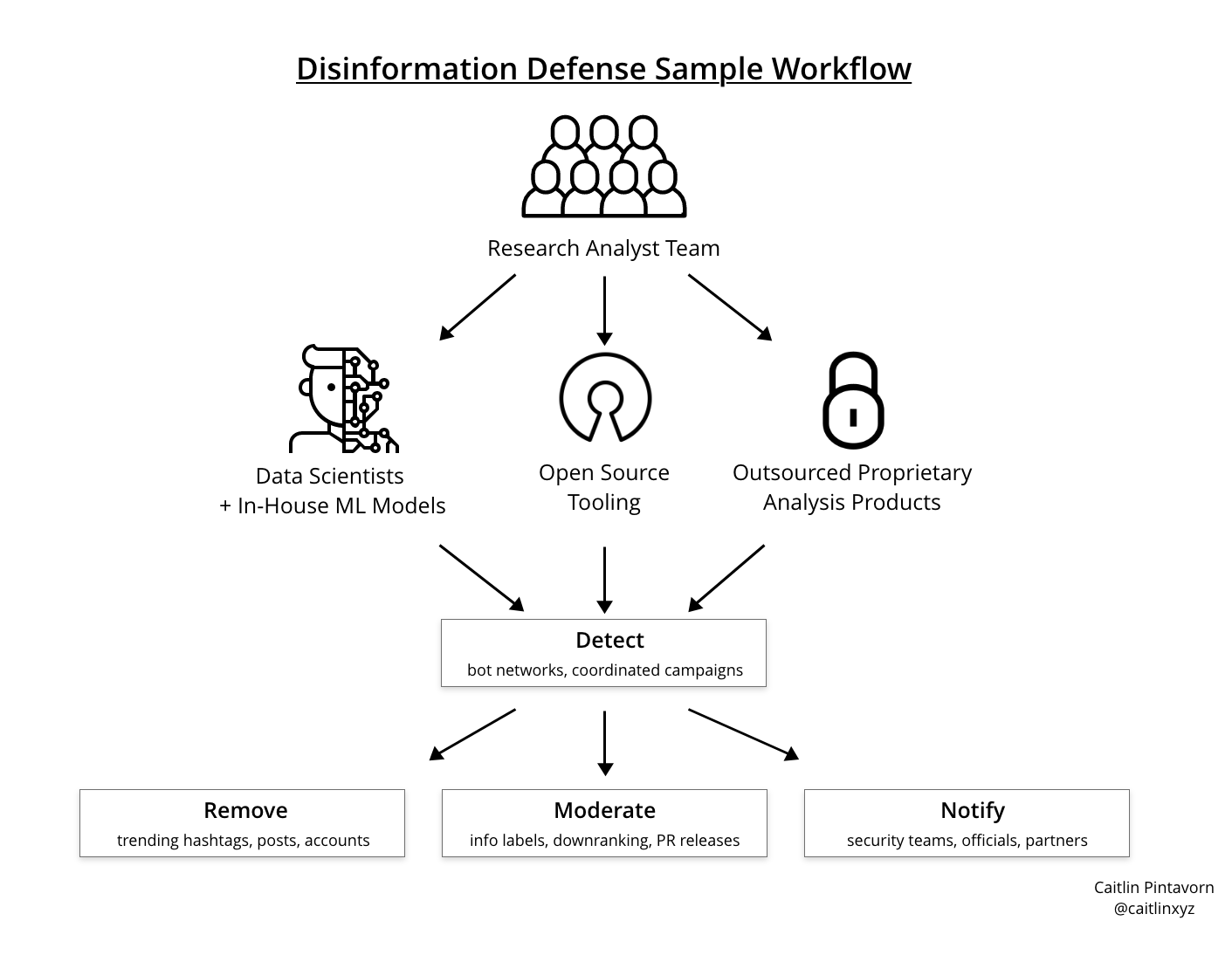
Detecting and combatting disinformation requires a lot of heavy-lifting. It involves the work and resources of large human research analyst teams who spend several hours a day unraveling complex disinformation networks and pinpointing superspreader nodes. And even when external and in-house research analysts notify affected platforms, it can be difficult to convince businesses that profit off of ad revenues to effectively alter their algorithms to push less viral, less engaging content. This is why we’ve seen such drastically different responses to controlling disinformation across big tech platforms, from Facebook’s more conservative attempts to Twitter’s unprecedented application of fact-checking labels to tweets.
The result of all of this work has been two dominating reactions across big tech platforms: 1) the application of information and fact-check labels and 2) the introduction of interruptions in the user experience flow.

The Issue with Big Tech’s Approach
But fact-checking and information labels can be confusing (using ambiguous language like “mostly false” and “this claim is disputed”) and instead draw more attention to the false information. It may help the relatively well-informed users, but it does little to impact those who are truly misinformed, the preferred targets.
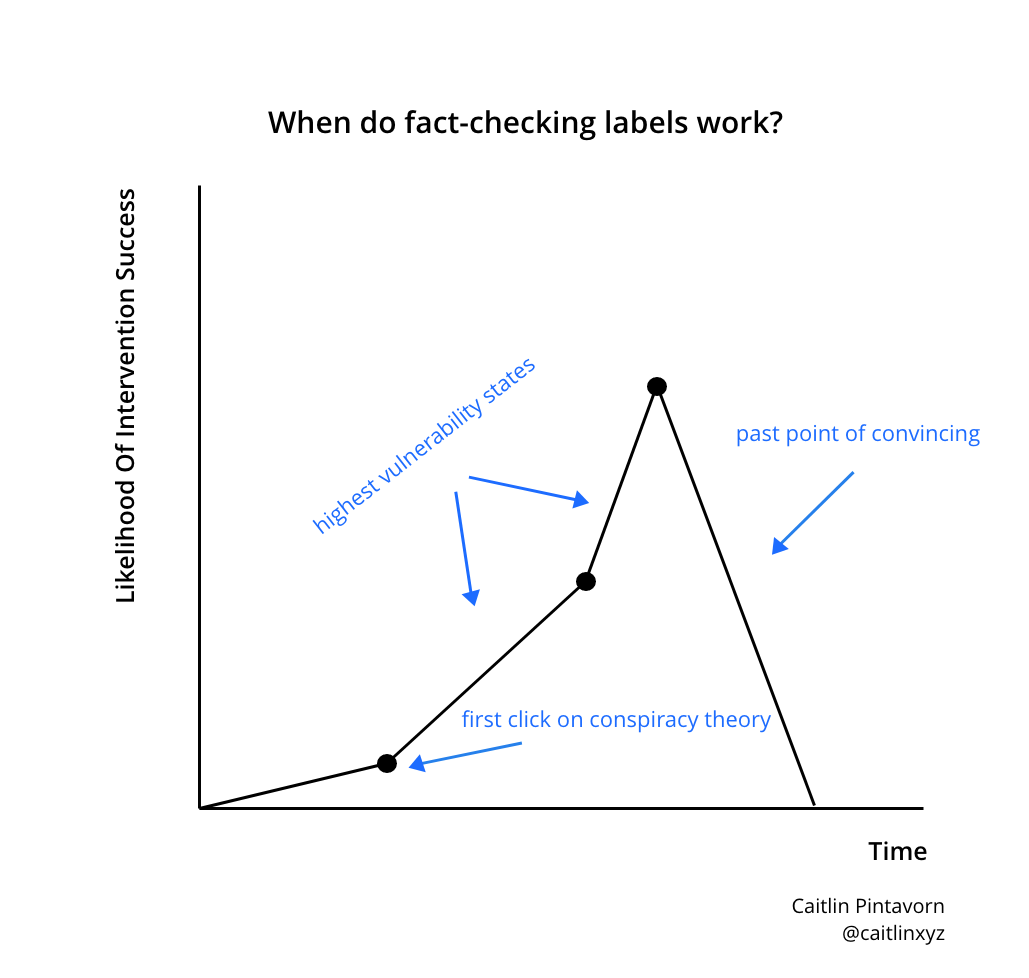
One issue lies within timing, a lesson we can learn from public health “just-in-time” behavioral interventions, which I’ve applied towards fact-checking in the graph below. Once a user is first served misleading or maliciously-driven false information, they’ll enter into a more vulnerable state where they’re subjected to similar content by recommendation algorithms. This is when they’d likely benefit from the introduction of counterpoints. However, after a certain point, it’s unlikely a fact-checking label can do much to convince them to believe anything else.
Another issue lies within UX interruptions. While these are perhaps a step-up from fact-checking labels because they can prevent the spread of disinformation — both in the creation of and social sharing of posts — they still fall short. The decision not to share false content falls heavily on the user themselves.
The Opportunity for Disinformation Startups
Current solutions effectively leave the task of solving disinformation up to ad-driven big tech and individual users. But what if we could instead realign financial incentives so that defending against disinformation became the more profitable venture? What if we could redirect where our revenues and attention go, away from disinformation-filled content in the first place? This is where the opportunity for disinformation defense startups lies.
We can think about the opportunity in what I’ll call our ground truth framework. The preservation of ground truth in a digital world revolves around 3 primary strategies —
- Authentication of Online Content: Is this image/video/audio fake or real? Is this piece of written information trustworthy or not? Is this user a bot or a real person?
- Detection of Falsehoods: How is this piece of disinformation spreading across networks? Who are the adversaries spreading it?
- Defense Against Disinformation Attacks: How do we mitigate the damage done? How do we prevent attacks in the first place?
Startups in this space represent a new category of modern cybersecurity: disinformation. I’ve mapped a few representative examples according to their primary value proposition within the framework below, given many span multiple categories.

Within authentication, there are a number of approaches being applied towards validating the authenticity of online content, which I’ll largely categorize into three groups: written text, digital media, and the users themselves. NewsGuard, for instance, has a bipartisan team of journalists apply ratings and information “nutrition labels” to thousands of news sites. Customers include Microsoft, which utilizes its real-time stream of data for its Bing search engine and provides its own users a Chrome extension that scores the trustworthy of links to news sites. In the realm of digital media, Truepic applies a form of secure watermarking for authenticating images and videos, which it then sells to enterprise customers like insurers and lending agencies. There are also startups focused on discerning between real and fake users. By this, I do not mean login authentication companies like Auth0 and Okta. Instead, these are startups that focus on bot detection as their core value prop since common tactics of spreading disinformation revolves around botnet and account takeover attacks. To this end, Kasadaworks to identify bots through fingerprinting website visitors and to remove financial incentivize by tricking the bot into solving impossible mathematical puzzles instead of carrying out malicious tasks.
For the detection use case, Primer leverages advanced NLP techniques to parse through unstructured data to analyze the spread of disinformation campaigns — a product that won them a multimillion dollar contract with the US government. Graphika, analyzes social networks to map out bad actors and identify unusual information propagations. For instance, they recently published a report with Facebook on a coordinated foreign campaign against maritime security using Generative Adversarial Networks (GANs) for a network of fake accounts.https://cdn.embedly.com/widgets/media.html?type=text%2Fhtml&key=a19fcc184b9711e1b4764040d3dc5c07&schema=twitter&url=https%3A//twitter.com/primer_ai/status/1333456065426583556&image=
Lastly, across defense, startups have worked to form novel business models to tackle disinformation. For example, Yonder applies ML to analyze disinformation narratives across social platforms and provide incident management solutions that protect brand integrity for customers like Bumble, Walmart, Johnson & Johnson, and Disney. Cyabra provides a similar SaaS solution towards defending against disinformation across social media, while also including visual deepfake detection in its product set. They sell their product to both brands and the public sector.
Standalone disinformation solutions have similarly drawn the attention of tech players like Adobe, which has been working on a project to spot image manipulations, and Microsoft, which has been working on a deepfake detector tool. This has led to a few notable acquisitions in the space such as Twitter’s 2019 acquisition of Fabula AI, which employs Geometric Deep Learning to detecting fake news at an impressive 93% success rate. In the future, there will likely be more acquisitions by other major technology and cybersecurity companies.
Final Thoughts: The Challenges Ahead
Technical Roadblocks
The disinformation space is nascent. There are a number of major technical bottlenecks that complicate the task at hand, and as adversaries become increasingly sophisticated, we’ll need to outpace disinformation innovation. For instance, audio manipulation via modulation and synthesis is an emerging form of deepfakes and is not as advanced as its visual counterparts. But there’s a chance it’ll become increasingly popular through creator tools like Descript for podcasting deepfakes and Modulate.ai for gaming voiceover deepfakes, creating a need to develop tools to detect manipulated audio. Resemble AI has already gotten started on this with its open source project Resemblyzer.
Designing for Disinformation
There’s also the issue of making appropriate design and product decisions to defend against disinformation. Choices in the way false information is presented (added copy, colors, placement) can have a significant impact on end user sentiment. As we’ve seen with some of the backlash against Twitter’s fact-checking and information labels, there’s a wide range of highly-politicized opinions on whether certain design decisions like overlays constitute censorship.
Unclear Regulatory Future
These ongoing debates between free speech and disinformation will result in continued attempts at regulation. California, for example, passed legislation to prohibit the use of deepfakes of political candidates within 60 days of an election. Texas went further, criminalizing deepfakes. However, similar to the ongoing debate about Section 230, these pieces of legislation will likely be contested and definitive outcomes will take years.
In any case, disinformation startups represent a new set of category-definers in the cybersecurity space, intensely fueled by a passion to restore truth and trust in the digital world. If you’re working on something here, I’d love to chat. You can email me at [email protected] or tweet at me @caitlinxyz.
About the Author
This submitted article was written by Caitlin Pintavorn of Insight Partners. See more at www.takeme.to/caitlin.